

今回はRを使って、人のツイートを分析していきます。
実際にどんな分析をしていくのか?というとポジティブなことばの割合とネガティブなことばの割合を出していきます。
例えばネガティブな言葉の割合が80%とかですね。
感情分析をするという感じですね。
今回の内容・概要
目的
RMeCabを使って、人のツイートを解析する。
ポジティブな言葉の割合が多いのか、ネガティブな言葉が多いのか調べる。
実行環境
- Window10
- R バージョン 3.4.4
必要なもの
- MeCab
- RMeCab
- PN Table
- TwitterAPI(アクセスキー・トークン)
必要なパッケージ
| TwitterAPIを使うための道具 | |
| dplyr | データフレームの操作が楽にできる |
| magrittr | パイプ演算子が使える。dplyrと相性良い |
| stringr | 文字列の処理をするため |
| RMeCab | 形態素分析するため |
人のツイートのポジティブとネガティブな割合を解析
流れ
- TwitterAPIに登録(アクセスキー・トークン取得)
- MeCabのインストール
- RMeCabのインストール・読み込み
↑は下準備です。
もしできていない方は、そこをクリックしてください。関連記事に飛びます。
また、MacやLinuxの場合は「MeCab R インストール」と調べていただくと、手順がでると思われます。
●アクセスキー・トークンも取得でき、RMeCabも使える状態の人
⑴ツイートのテキスト部分を活用できる形にする作業
- TwitterAPI認証
- ツイート取得
- テキスト部分取得
- いらない部分削除
- 文字コード変換
- ファイル作成
- 名詞・動詞など取得する
- 長い列名変える(好み)
⑵PN Tableを使える形にする
- PN Tableの読み込み
- データをわかりやすく見える形にする
- ⑴と結合
⑶ポジティブ・ネガティブ割合
- 割合を求める
- その他にもいろいろできる
⑴ツイートのテキスト部分を活用できる形にする作業
- TwitterAPI認証
- ツイート取得
- テキスト部分取得
- いらない部分削除
- 文字コード変換
- ファイル作成
- 名詞・動詞など取得する
- 長い列名変える(好み)
1.TwitterAPI認証
##1
#パッケージ読み込む
library(“twitteR”)
#下に自分のアクセスキー・トークン入力。””は残す
consumerKey <- “○○○○○○”
consumerSecret <- “○○○○○○”
accessToken <- “○○○○○○”
accessSecret <- “○○○○○○”
#認証
options(httr_oauth_cache = TRUE)
setup_twitter_oauth(consumerKey, consumerSecret, accessToken, accessSecret)
#”Using direct authentication”が表示されたら成功エラーが出た場合はtwitterRに依存しているパッケージが必要になります。このパッケージ不安定が売りなんでね。
- “base64enc”
- “bit64”
- “rjson”
- “DBI”
- “httr”
この子たちもエラー起こしたら、インストールして読み込んでいきましょ。
2.ツイート取得
##2
#ツイートの取得
tweets <- userTimeline(“gumimomoko”, 1000)| userTimeline("○○", 取得するツイート数) | @○○のツイートを取得 |
「1000」じゃなくてもかまいませが、20000とかやってくとTwitterAPIに制限がかかってしまい使えなくなってしまう場合があります。
とりあえず「1000」でいきましょ。あと「1000」にしたからといって、1000ツイートを取得できるわけでもありません。
なんか300とか500とかになったりします。そういう仕様なので、気にしないでください。
3.テキスト部分取得
##3
#テキスト部分を取る
texts <- sapply(tweets, statusText)| sapply(A, statusText) | Aのテキスト部分を取る |
さきほど取得したツイートには、多くいらない部分が含まれています。「tweets」で実行してみるとわかりますので、興味ある方は是非。
そのツイートのテキスト部分だけを取っていきます。
4.いらない部分削除
##4
#パッケージの読み込み
library(dplyr)
library(magrittr)
library(stringr)
#いらない記号(ID・URL・記号)を取り除くことができるASCLL
texts %<>% str_replace_all(“\\p{ASCII}”, “”)
# 欠損値を省く
texts <- texts[!is.na(texts)]ツイートのテキスト部分を抽出したとしても、まだ無駄な部分があります。
それも取り除いていきます。
5.文字コード変換(Windowのみ)
##5
#windowsのみ文字コード変換
texts <- iconv(texts , from = “UTF-8”, to = “CP932”)Mac・Linuxはこの作業はスルーでお願いします。
6.ファイル作成
##6
#ファイルの結合と保存
#取得したツイートを一つのファイルにして保存
texts2 <- paste(texts, collapse =””)
# 一時的なファイルを作る
xfile <- tempfile()
#先ほどのファイルに結合したツイートを書きだす
write(texts2, xfile)ファイルにしなくてもできると思ったんですが、できなかったので、一度ファイルにします。
7.名詞・動詞など取得する
##7
#名詞・動詞などの残す部分を決める
library(RMeCab)
twitext <- docDF(xfile, type = 1, pos = c(“動詞”,”名詞”,”形容詞”))
twitext %<>% filter(!POS2 %in% c(“サ変接続”,”非自立”,”数字”,”接尾”))当然、名詞だけ、動詞だけということもできます。
また「動詞、名詞、形容詞」の中で「サ変接続、非自立、数字、接尾」を含むものを除去してます。
8.長い列名変える(好み)
##8
#列名の変更(FREQにする)
twitext %<>% select(everything(), FREQ = starts_with(“file”))
#さっき作った一時的ファイルを消す
unlink(xfile)【R】TwitterAPIとMeCabとwordcloud使い、人のツイートの単語出現頻度を可視化するで変更したように、こちらも変更していきます。
こっちの方が見やすいです。
⑴のコード全体
##1
#パッケージの読み込む
library(“twitteR”)
#下に自分のアクセスキー・トークン入力。””は残す
consumerKey <- “○○○○”
consumerSecret <- “○○○○”
accessToken <- “○○○○”
accessSecret <- “○○○○”
#認証
options(httr_oauth_cache = TRUE)
setup_twitter_oauth(consumerKey, consumerSecret, accessToken, accessSecret)
#”Using direct authentication”が表示されたら成功
##2
#ツイートの取得
tweets <- userTimeline(“gumimomoko”, 1000)
##3
#テキスト部分を取る
texts <- sapply(tweets, statusText)
##4
#いらない部分の削除
library(dplyr)
library(magrittr)
library(stringr)
#いらない記号(ID・URL・記号)を取り除くことができるASCLL
texts %<>% str_replace_all(“\\p{ASCII}”, “”)
# 欠損値を省く
texts <- texts[!is.na(texts)]
##5
#windowsのみ文字コード変換
texts <- iconv(texts , from = “UTF-8”, to = “CP932”)
##6
#ファイルの結合と保存
#取得したツイートを一つのファイルにして保存
texts2 <- paste(texts, collapse =””)
# 一時的なファイルを作る
xfile <- tempfile()
# 先ほどのファイルに結合したツイートを書きだす
write(texts2, xfile)
##7
#名詞・動詞などの残す部分を決める
library(RMeCab)
twitext <- docDF(xfile, type = 1, pos = c(“動詞”,”名詞”,”形容詞”))
twitext %<>% filter(!POS2 %in% c(“サ変接続”,”非自立”,”数字”,”接尾”))
##8
#列名の変更
#列名をFREQにする
twitext %<>% select(everything(), FREQ = starts_with(“file”))⑵PN Tableを使える形にする
- PN Tableの読み込み
- データをわかりやすく見える形にする
- ⑴と結合
1.PN Tableの読み込み
##1
#windows
pn <- read.table(“http://www.lr.pi.titech.ac.jp/~takamura/pubs/pn_ja.dic”,
sep = “:”, stringsAsFactors = FALSE)
#Mac.Linux
pn <- read.table(“http://www.lr.pi.titech.ac.jp/~takamura/pubs/pn_ja.dic”,
sep = “:”, stringsAsFactors = FALSE,fileEncoding = “CP932”, encoding = “UTF-8”)| read.table(URL) | URLの表読み込み |
ポジティブな言葉とネガティブな言葉が書いてある表を読み込んでいきます。
head(pn)これでしっかりURLが読み込みができたか、確認できます。
2.データをわかりやすく見える形にする
##2
#一部抽出・名前変更
pn2 <- pn %>% select(V1, V4) %>% rename(TERM = V1)
pn2 %<>% distinct(TERM, .keep_all = TRUE)
#データ表示
head(pn2)| select(V1, V4) %>% rename(TERM = V1) | V1,V4を選択し、V1の列名をTERMにする |
| distinct(TERM, .keep_all = TRUE) | TEAMで重複しているものを削除 |
名前を変えたのは長いからです。また、名詞とか自立語とかの表示はいらないので、削除してます。
head(pn2)を実行するとこんな感じになります。名前がしっかり変わってますね。
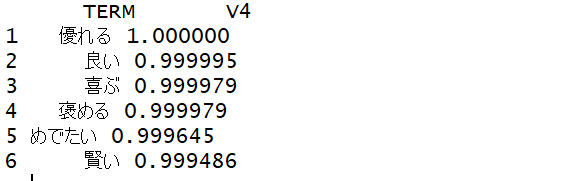
3.⑴と結合
##3
#⑴結合
twitext2 <- twitext %>% left_join(pn2)
#データ表示
head(pn2)
#TERM V4だけ選んで表示
twitext2 %>% select(TERM, V4) %>% arrange(V4) %>% head(10)| twitext %>% left_join(pn2) | twitextにpn2を結合させる |
2018/4/19日現在
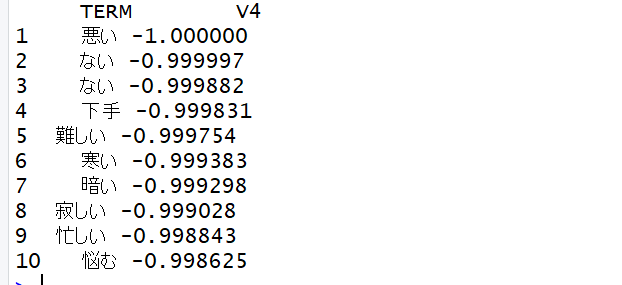
⑵全体コード
###⑵
##1
#windows
pn <- read.table(“http://www.lr.pi.titech.ac.jp/~takamura/pubs/pn_ja.dic”,
sep = “:”, stringsAsFactors = FALSE)
#Mac.Linuxの方
pn <- read.table(“http://www.lr.pi.titech.ac.jp/~takamura/pubs/pn_ja.dic”,
sep = “:”, stringsAsFactors = FALSE,fileEncoding = “CP932”, encoding = “UTF-8”)
head(pn)
##2
#一部抽出・名前変更
pn2 <- pn %>% select(V1, V4) %>% rename(TERM = V1)
pn2 %<>% distinct(TERM, .keep_all = TRUE)
#データ表示
head(pn2)
##3
#⑴結合
twitext2 <- twitext %>% left_join(pn2)
head(pn2)
#TERM V4だけ選んで表示
twitext2 %>% select(TERM, V4) %>% arrange(V4) %>% head(10)⑶ポジティブ・ネガティブ割合
- ネガティブとポジティブな言葉の割合を求める
1.ネガティブとポジティブな言葉の割合を求める
##3
#ポジティブ・ネガティブ割合
poji <- twitext2 %>% summarize( sum (V4 > 0, na.rm = T))
nega <- twitext2 %>% summarize( sum (V4 < 0, na.rm = T))
#ネガティブな割合
print(nega/(poji+nega))| summarize( sum (V4 > 0, na.rm = T)) | V4>0以上はポジティブな言葉の割合。na.rm=Tは欠損値を無視してくれる |
PN Tableでは、ポジティブな言葉は0以上、ネガティブな言葉は0以下に表されています。
そこでポジティブな言葉をpoji、ネガティブな言葉をnega変数にいれます。さらにnega/(poji+nega)を行うことでネガティブな言葉を表示することができます。
他にも色々できるので、追記していきます。
⑶全体コード
###⑶
##1
#ポジティブ・ネガティブ割合
poji <- twitext2 %>% summarize( sum (V4 > 0, na.rm = T))
nega <- twitext2 %>% summarize( sum (V4 < 0, na.rm = T))
#ネガティブな割合
print(nega/(poji+nega))全体コード
###⑴
##1
#パッケージの読み込む
library(“twitteR”)
#下に自分のアクセスキー・トークン入力。””は残す
consumerKey <- “○○○○”
consumerSecret <- “○○○○”
accessToken <- “○○○○”
accessSecret <- “○○○○”
#認証
options(httr_oauth_cache = TRUE)
setup_twitter_oauth(consumerKey, consumerSecret, accessToken, accessSecret)
#”Using direct authentication”が表示されたら成功
##2
#ツイートの取得
tweets <- userTimeline(“gumimomoko”, 1000)
##3
#テキスト部分を取る
texts <- sapply(tweets, statusText)
##4
#いらない部分の削除
library(dplyr)
library(magrittr)
library(stringr)
#いらない記号(ID・URL・記号)を取り除くことができるASCLL
texts %<>% str_replace_all(“\\p{ASCII}”, “”)
# 欠損値を省く
texts <- texts[!is.na(texts)]
##5
#windowsのみ文字コード変換
texts <- iconv(texts , from = “UTF-8”, to = “CP932”)
##6
#ファイルの結合と保存
#取得したツイートを一つのファイルにして保存
texts2 <- paste(texts, collapse =””)
# 一時的なファイルを作る
xfile <- tempfile()
# 先ほどのファイルに結合したツイートを書きだす
write(texts2, xfile)
##7
#名詞・動詞などの残す部分を決める
library(RMeCab)
twitext <- docDF(xfile, type = 1, pos = c(“動詞”,”名詞”,”形容詞”))
twitext %<>% filter(!POS2 %in% c(“サ変接続”,”非自立”,”数字”,”接尾”))
##8
#列名の変更
#列名をFREQにする
twitext %<>% select(everything(), FREQ = starts_with(“file”))
###⑵
##1
#windows
pn <- read.table(“http://www.lr.pi.titech.ac.jp/~takamura/pubs/pn_ja.dic”,
sep = “:”, stringsAsFactors = FALSE)
#Mac.Linuxの方
pn <- read.table(“http://www.lr.pi.titech.ac.jp/~takamura/pubs/pn_ja.dic”,
sep = “:”, stringsAsFactors = FALSE,fileEncoding = “CP932”, encoding = “UTF-8”)
head(pn)
##2
#一部抽出・名前変更
pn2 <- pn %>% select(V1, V4) %>% rename(TERM = V1)
pn2 %<>% distinct(TERM, .keep_all = TRUE)
#データ表示
head(pn2)
##3
#⑴結合
twitext2 <- twitext %>% left_join(pn2)
head(pn2)
#TERM V4だけ選んで表示
twitext2 %>% select(TERM, V4) %>% arrange(V4) %>% head(10)
###⑶
##1
#ポジティブ・ネガティブ割合
poji <- twitext2 %>% summarize( sum (V4 > 0, na.rm = T))
nega <- twitext2 %>% summarize( sum (V4 < 0, na.rm = T))
#ネガティブな割合
print(nega/(poji+nega))ちょっとネガティブな割合が大きくなるような印象です。以上RMeCabを使って人のツイートのポジティブとネガティブな割合を表示するという話でした。またR言語はUdemyでも学べます。
参考にさせてもらった記事・データ
東工大学の高村研究室で公開している「PN Table」を利用させていただきました。 とても便利なツールです。
研究を行う人は必見です。











コメント