

複雑なHTMLサイトから、スクレイピングするのは大変です。普通に、意味わかんないサイトがあります。そこで簡単なHTMLで構成されたサイトから、スクレイピングしてみます。
スクレイピングするサイト
石田基広さんのサイトを使います。一度、ご覧ください。
「Rによるスクレイピング入門」という本を参考にさせていただきます。
サイト自体は、めっちゃシンプルですよね。
だからこそ、スクレイピングの勉強となります。
今回使うパッケージ
| パッケージ名 | 説明 |
| rvest | Webページから情報を抽出する作業を簡単にしてくれる |
| dplyr | データフレームを簡単に操作できる(パイプ演算子を使う) |
| magrittr | オブジェクトの一部の抽出または置換(パイプ演算子を使う) |
DOMを理解する
サイト内のURLを取得したい!
テキスト部分を取得したい!
と考えても、HTMLドキュメント(サイトにアクセスして表示されるもの)のまま、Rで読み込むことはできません。
htmlドキュメントをツリー構造にした「DOM」というものから、スクレイピングします。
HTMLドキュメント
▼
DOM
▼
スクレイピング
このような流れとなります。
大事な部分なので、「DOM」について見ていきます。
DOMはHTMLドキュメントのツリー構造化したもの
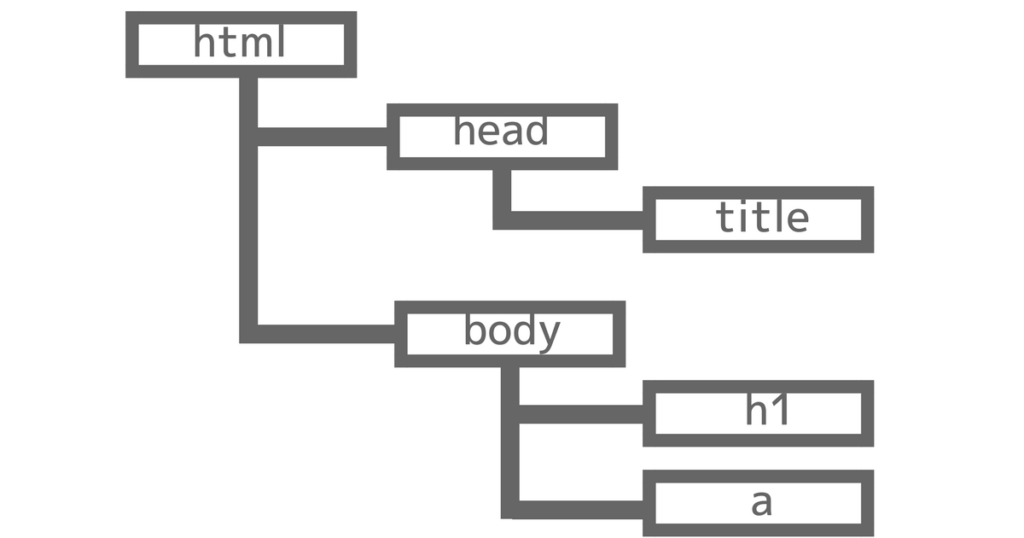
DOMはHTMLドキュメントの要素をツリー構造化したものです。
上の図をご覧ください。
ツリー構造のようになっているのがなんとなくわかりますよね。
【html】という木に【head】という枝があり、その枝から【title】という枝が存在している。
【html】という木に【body】という枝があり、その枝から【h1】【a】という枝が存在している。
また、【html】は【head】の親要素、【head】は【html】の子要素のように、親子関係で言われることもあります。
要素をノードという
もう一度、先ほどの図をご覧ください。
DOMでは、HTMLドキュメント内の要素をノードいいます。【html】【body】【title】【a】【h1】すべて、ノードと言います。
ノード、子ノード、 親ノード、 兄弟姉妹ノードなどノードによって名前は違いますが、説明を省きます(今回は重要ではない)
HTMLドキュメントをDOMにして読み込む
DOMの説明が長くなりましたが、HTMLドキュメントを読み込んでいきます。
先にパッケージを読み込んでいきます。
library(rvest)
library(dplyr)
library(magrittr)read_html()でDOMという構造にしていきます。
test <- read_html(“https://ishidamotohiro.github.io/sample_check/simple.html”)
test ▼のような結果になります。
{xml_document}
<html>
[1] <head>n<meta http-equiv=”Content-Type” content=”text/html; charset=U …
[2] <body>n <h1>大見出し</h1>n <a href=”http://www.okadajp.org/RWiki/ …<html>という木に<head>、<body>という枝があるようなことがわかれば、大丈夫。DOMにできれば、要素を抽出することが可能になります。
大見出し(h1)要素の抽出
test %>% html_nodes(“h1”)
test{xml_nodeset (1)}
[1] <h1>大見出し</h1>という結果になります。html_nodes()でh1ノードを指定しています。これによって、h1要素全体を取り出すことが可能です。
test %>% html_nodes(“h1”) %>% html_text()
test[1] "大見出し"という結果になります。h1要素の中の要素(テキスト)の部分を、抽出したということですね。
リンクのURLの取り出し
URLを取り出します。
test %>% html_nodes("a") %>% html_attrs()[[1]]
href
"http://www.okadajp.org/RWiki/"
[[2]]
href target
"http://rmecab.jp" "_blank"html_nodes()でa要素を抽出して、html_attrs()でURLを取り出しています。
属性の値だけを抽出
test %>% html_nodes("a") %>% html_attr("href")[1] "http://www.okadajp.org/RWiki/" "http://rmecab.jp"この結果となります。
hrefという属性の値を抽出することが出来ます。
指定されたノードが出てくる最初の要素を抽出
test %>% html_node("a")<a href="http://www.okadajp.org/RWiki/">という結果になります。html_node()で指定したノードが出てくる、最初の要素を抽出します。
番号指定して属性の値を抽出
1番目に出てくるURLを抽出、2番目に出てくるURLを抽出など、決めることができます。magrittrパッケージのextract()を使います。
test %>% html_nodes("a") %>% html_attr("href") %>% extract(1)"http://www.okadajp.org/RWiki/"この結果になります。html_nodesでa要素を抽出して、URLを取り出し、その一番目を表示といった感じです。extract(1)→extract(2)にすれば、二番目のURLを抽出することができます。
まとめ
- スクレイピングにはDOMを使う
- ノードを使って、抽出する
- %>%演算子を使うと、わかりやすい
UdemyでR言語について学ぶこともできます。以上Rを使ってHTMLドキュメントのスクレイピングするという話でした。












コメント