

R言語を使ってスクレイピングする方法が知りたい
という人向けの記事です。
XPathとは?
XPathはXML文章中の要素、属性値などを指定するための言語。
XMLってのは、情報の管理をするための言語みたいな感じですわ(今は、知らなくて良いです)
じゃあXMLで書かれたものしか、スクレイピングできないのか?そんなことはないです。
HTMLはXMLの一部です。
DOMに似ている
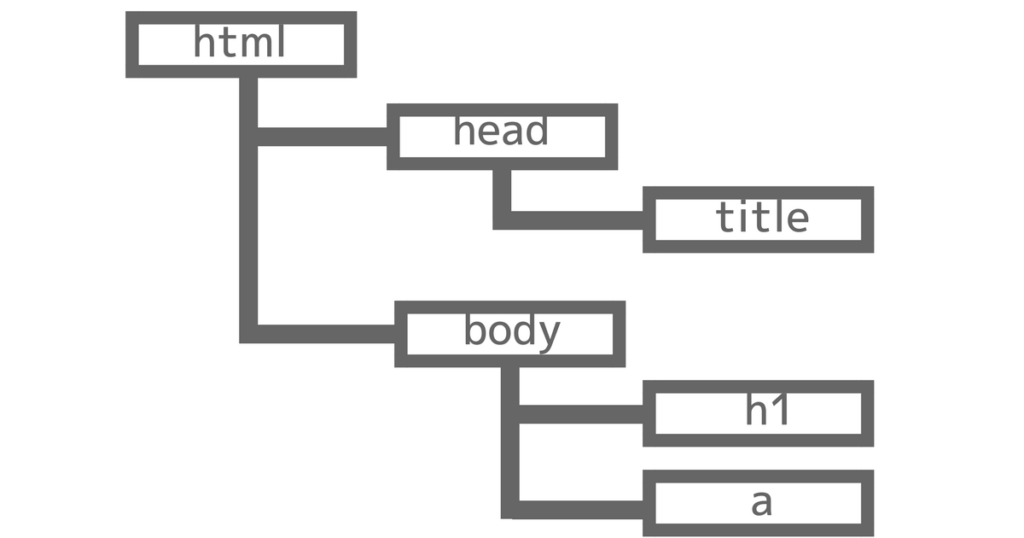
以前の記事で、DOMがツリー構造になっているという話をしました。
XPathもXML(HTML)をツリー構造として、考えています。ちょっくら思い出しておいてください。
スクレイピングするサイト
石田基広さんのサイトを使います。一度、ご覧ください。
「Rによるスクレイピング入門」という本を参考にさせていただきます。
サイト自体は、めっちゃシンプルですよね。石田基広さんのサイトは、スクレイピングをする際に、とても勉強となります。
今回使うパッケージ
| パッケージ名 | 説明 |
| rvest | Webページから情報を抽出する作業を簡単にしてくれる |
| dplyr | データフレームを簡単に操作できる(パイプ演算子を使う) |
| magrittr | オブジェクトの一部の抽出または置換(パイプ演算子を使う) |
HTMLでスクレイピングするときと同様に、HTMLドキュメントを読み込みする必要があります。
HTMLドキュメントをDOMにして読み込む
いつも通り、この作業をお願いします。
library(rvest)
library(magrittr)
library(dplyr)rvestのread_htmlを使って、DOMという構造にしていきます。
test3 <- read_html("https://IshidaMotohiro.github.io/sample_check/simple2.html"){xml_document}
<html>
[1]<head>n<meta http-equiv="Content-Type" content="text/html; charset=U ...
[2] <body>n <div>n <p>pタグ</p>n </div>n <p class="green">classを使 .ページのソースを確認
左HTMLドキュメント
右HTMLソースコード


XPathを使って要素を抽出する際には、ページのソースを見る必要があります。
ソースコードを見るには、【右クリック】→【ページのソースを表示】でみることができます(ブラウザによって変わる)
ツリー構造を確認する
<html>要素の下に<body>要素、その下に<p>要素が2つあります。<p class="green">classを使った例</p>と<p id="red">idを使った例</p>です。
xpath的にいうと、/html/body/p というように表記します。
<html>要素の下に<body>要素、その下に<div>要素、その下にp要素があります。<p>pタグ</p>です。
xpath的にいうと、/html/body/div/p というように表記します。
なんとなくわかりますよね。
html要素という大きな木に、だんだん枝が生えてきてるような感じです。このようなツリー構造は大事です。
ツリー構造(階層)全て表記して抽出
では、xpathを利用して、抽出していきます。
test3 %>% html_nodes(xpath = “/html/body/p”)
test3{xml_nodeset (2)}
[1] <p class=”green”>classを使った例</p>
[2] <p id=”red”>idを使った例</p>のような結果になります。
XPathを利用するときは、xpath = "ツリー構造(階層)"のように表記します。
/html/body/pはhtml要素の下にあるbody要素、その下にあるp要素を指定してます。
test3 %>% html_nodes(xpath = “/html/body/div/p”)
test3{xml_nodeset (1)}
[1] <p>pタグ</p>の結果になります。html要素の下にあるbody要素、その下にあるdiv要素、その下にあるp要素を指定して、抽出しています。
XPathの基本です。理解しておくことをおすすめします。
値(テキスト)部分を抽出
HTMLやCSSのときと同様、要素の値(テキスト)部分を抽出することもできます。
test3 %>% html_nodes(xpath = "/html/body/p") %>% html_text()[1] "classを使った例" "idを使った例"html_nodes(xpath="/html/body/p") でp要素を指定して、html_text()で値(テキスト部分)を抽出しています。
ツリー構造(階層)を無視して抽出
html要素とかbody要素とか気にしないで、とにかくp要素を抽出したい
そのようなこともできます。
test3 %>% html_nodes(xpath = "//p")[1] <p>pタグ</p>
[2] <p class="green">classを使った例</p>
[3]<p id="red">idを使った例</p>//pで階層が異なる要素でも、抽出することができます。
test3 %>% html_nodes(xpath = "//p") %>% html_text()とうぜん、テキスト部分を抽出することができます。
一部固定で階層を気にしないで抽出(直接的)
ある要素の下にある要素のみを抽出することもできます。
body要素の下にあるp要素のみを抽出します。
test3 %>% html_nodes(xpath = "//body/p"){xml_nodeset (2)}
[1] <p class="green">classを使った例</p>
[2] <p id="red">idを使った例</p>この結果になります。body要素の下にある要素のみなので、div要素の下にあるp要素は抽出されません。
一部固定で階層を完全に気にしないで抽出(直接的・間接的)
ある要素の下にある要素をすべて抽出したい
ということもできます。
先ほどの場合は、ある要素と下にある要素(直接的に触れている要素)のみを抽出しました。今回は、間接的に触れている要素も抽出できます。
▼このコード合っているかわかりません。すいません。▼
test3 %>% html_nodes(xpath = "//body//p"){xml_nodeset (3)}
[1] <p>pタグ</p>
[2] <p class="green">classを使った例</p>
[3] <p id="red">idを使った例</p>//bodyでbody要素の下にある要素を指定して、//pでbody要素の下に直接的にある要素やdiv要素の下にある要素をすべて、抽出しています。
descendantを利用
直線的・間接的に触れている要素を、「descendant」を利用することで、抽出できます。
test3 %>% html_nodes(xpath = "//body/descendant::p"){xml_nodeset (3)}
[1]<p>pタグ</p>
[2]<p class="green">classを使った例</p>
[3]<p id="red">idを使った例</p>この結果になります。
要素1/descendant::要素2とすることで、要素1の下に直線的に触れている要素と間接的に触れている要素を抽出できます。
まとめ
- XPathはXML文章中の要素、属性値などを指定するための言語
- XMLの一部にHTMLが含まれている
- HTMLをツリー構造として考えて、XPathを使う
以上Rを使ってXPathをスクレイピングする方法でした。またR言語はUdemyでも学べます。












コメント